IT之家 8 月 24 日音问,英伟达邀请部分媒体举办吹风会,向科技记者初次展示了 Blackwell 平台。英伟达将出席 8 月 25-27 日举办的 Hot Chips 2024 活动,展示 Blackwell 平台在数据中心参预使用的商量情况。


否定 Blackwell 推迟上市音问
英伟达在本次吹风会上,驳倒了 Blackwell 推迟上市的音问,并共享了更多数据中心 Goliath 的商量信息。

英伟达在吹风会献艺示了 Blackwell 在其一个数据中心的开动情况,并强调 Blackwell 正在按策动鼓舞,并将于本年晚些期间向客户发货。

有音问称 Blackwell 存在某种劣势或问题,本年无法投放市集,这种说法是站不住脚的。
Blackwell 简介
英伟达示意 Blackwell 不单是是一款芯片,它如故一个平台。就像 Hopper 相通,Blackwell 包含面向数据中心、云计算和东说念主工智能客户的无数联想,每个 Blackwell 家具齐由不同的芯片构成。

IT之家附上包括的芯片如下:
Blackwell GPU
Grace CPU
NVLINK Switch Chip
Bluefield-3
ConnectX-7
ConnectX-8
Spectrum-4
Quantum-3
Blackwell 桥架
英伟达还共享了 Blackwell 系列家具中多样桥架的全新图片。这些是初次共享的 Blackwell 桥架图片,展示了联想下一代数据中心平台所需的无数专科工程工夫。



策动万亿参数 AI 模子
Blackwell 旨在满足当代东说念主工智能的需求,并为大型说话模子(如 Meta 的 405B Llama-3.1)提供出色的性能。跟着 LLMs 的规模越来越大,参数也越来越多,数据中心将需要更多的计算和更低的延长。
多 GPU 推理程序
多 GPU 推理程序是在多个 GPU 上进行计算,以得回低延长和高隐隐量,炒股的但摄取多 GPU 阶梯也有其复杂性。多 GPU 环境中的每个 GPU 齐必须将计算礼貌发送给每一层的其他 GPU,这就需要高带宽的 GPU 对 GPU 通讯。

多 GPU 推理程序是在多个 GPU 上进行计算,以得回低延长和高隐隐量,但摄取多 GPU 阶梯也有其复杂性。多 GPU 环境中的每个 GPU 齐必须将计算礼貌发送给每一层的其他 GPU,这就需要高带宽的 GPU 对 GPU 通讯。
更快的 NVLINK 交换机
通过 Blackwell,NVIDIA 推出了速率更快的 NVLINK 交换机,将结构带宽提高了一倍,达到 1.8 TB/s。NVLINK 交换机自己是基于台积电 4NP 节点的 800mm2 芯片,可将 NVLINK 扩张到 GB200 NVL72 机架中的 72 个 GPU。


该芯片通过 72 个端口提供 7.2 TB/s 的全对全双向带宽,网内计算才气为 3.6 TFLOPs。NVLINK 交换机托盘配有两个这么的交换机,提供高达 14.4 TB/s 的总带宽。

水冷散热
英伟达摄取水冷散热,来莳植性能和效果。GB200、Grace Blackwell GB200 和 B200 系统将摄取这些新的液冷处置有打算,可将数据中心才气的电力资本最多裁汰 28%。

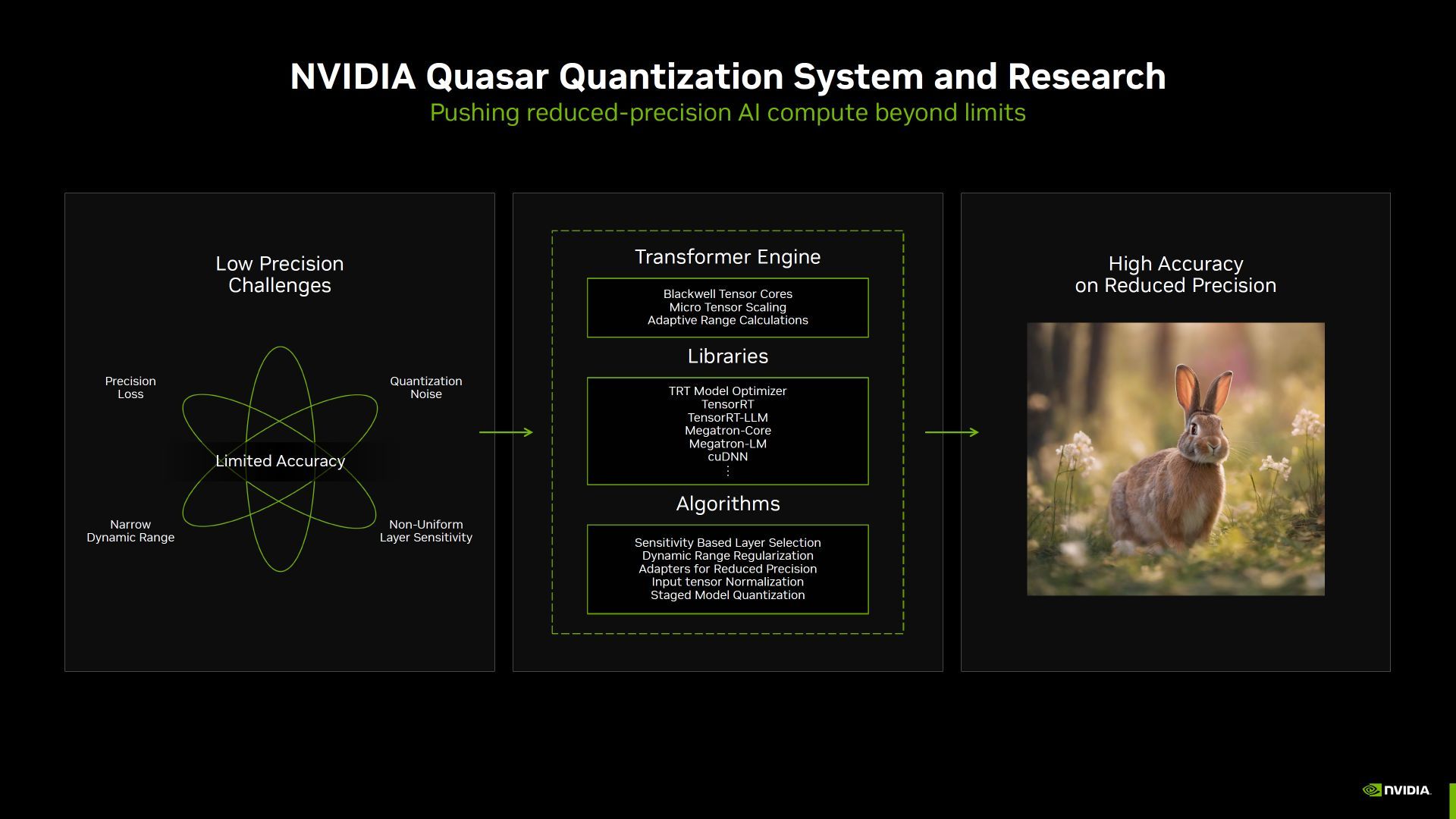
首张使用 FP4 计算生成的东说念主工智能图像
英伟达™(NVIDIA®)还共享了大众首张使用 FP4 计算生成的东说念主工智能图像。图中知道,FP4 量化模子生成的 4 位兔子图像与 FP16 模子相配相似,但速率更快。

该图像由 MLPerf 在郑重扩散中使用 Blackwell 制作而成。刻下,裁汰精度(从 FP16 到 FP4)所面对的挑战是会耗损一些精度。